在写代码的时候,我发现以下两种代码编写方式,看起来都是多线程,但是其运行时间,和线程对象却有差别,这种情况我以前忽视了,现记录一下。
代码示例如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import threading
import time
class CodingThread(threading.Thread):
def run(self):
print('%s正在写代码' % threading.current_thread())
class DrawingThread(threading.Thread):
def run(self):
print('%s正在画图' % threading.current_thread())
def multi_thread():
for _ in range(5):
CodingThread().start()
for _ in range(5):
DrawingThread().start()
if __name__ == '__main__':
start = time.time()
multi_thread()
print('共耗时:',time.time()-start)
输出:
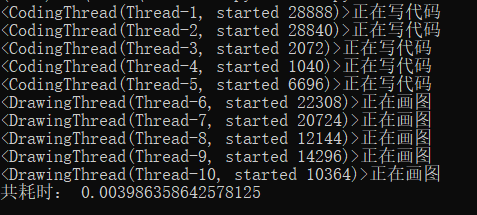
1 | #代码二 |
输出:
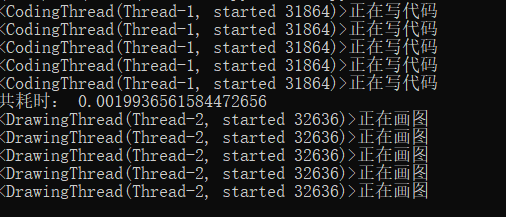
不难看出,第一个代码执行时,调用了10个不同的线程对象,并且其子线程全部结束之后主线程才输出耗时时间并结束。但是代码二执行时,只调用了2个线程对象,主线程并不会等待子线程结束。
个人分析其原因,是因为start()方法决定了线程的分配。例如代码一中,对for循环中的每一个操作都单独分配了一个线程,所以总共循环十次,有十个线程,等待循环结束后,主线程才结束。但在代码二中,将继承了threading.Thread的类单独分配了线程,所以有2个类,就有两个线程,类中的for循环是在同一个线程之中完成的,所以主线程不会等待子线程结束。
另外,我发现代码一的运行时间要比代码二要长,但是以上示例代码的循环次数太少,对比不够明显,并且代码二中主线程可能会先于子线程执行完毕,所以将循环次数都改为10000,再将代码二改写一下,把multi_thread()函数中的注释行取消,如下:1
2
3
4
5
6
7
8def multi_thread():
t1 = CodingThread()
t2 = DrawingThread()
t1.start()
t1.join()
t2.start()
t2.join()
在《多线程&多进程(上)》中也已经说明了join()可以使主线程等待子线程执行完之后再关闭,所以改写过后就可以计算整个程序运行的时间了。
改写后的代码输出如下:
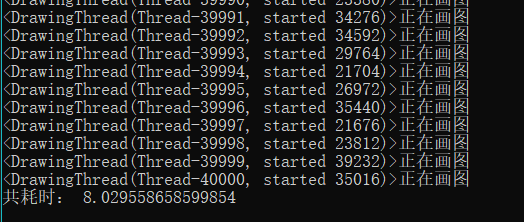
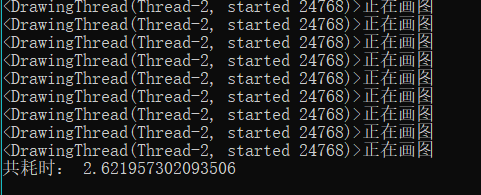
是什么造成了这样的差距呢?我分析是因为代码一不断的切换线程,造成了一部分开销,而代码二只在两个线程中完成操作,就少了切换线程的开销,所以切换线程次数多的代码一耗时长。而我们知道切换进程的开销比线程还要大,所以还需对比一下多进程的效果。
错误之处希望大神指出。