在《多线程&多进程(上)》中,记录了python中的threading模块常用的类的使用方法,对比了Lock/RLock和condition版本的生产者与消费者的问题,但是python中并不支持真正的支持多线程,不能充分的利用多核cpu的资源,大部分情况下使用的是多进程。在下半部分中,将记录多进程的使用。
多进程
官方文档
multiprocessing模块常用的类和方法(脑图)
本节将介绍:
- Process(用于创建进程模块)
- Pool(用于创建管理进程池)
- Queue(用于进程通信,资源共享)
- Lock
- Pipe(用于管道通信)
- Semaphore
Process模块
- 基本使用
在multiprocessing中,每一个进程都用一个Process类来表示。其用法和Thread对象的用法很相似,也有start(),run(),join()等方法。Process类适合简单的进程创建,如需资源共享可以结合multiprocessing.Queue使用;如果想要控制进程数量,则建议使用进程池Pool类。
首先看下它的API1
Process([group [, target [, name [, args [, kwargs]]]]])
- target:调用对象,你可以传入方法的名字。
- args:被调用对象的位置参数元组,比如target是函数a,他有两个参数m,n,那么args就传入(m, n)即可。
- kwargs:调用对象的字典。
- name:别名,相当于给这个进程取一个名字。
- group:线程组,目前还没有实现,库引用中提示必须是None。
其包含以下实例方法,和Thead类似:
| 方法 | 说明 |
|---|---|
| is_alive() | 返回进程是否在运行 |
| join([timeout]) | 阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数) |
| start() | 进程准备就绪,等待CPU调度 |
| run() | strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法。 |
| terminate() | 不管任务是否完成,立即停止工作进程。 |
Process类中创建多进程有两种方法:
(1)用法与threading类似1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17from multiprocessing import Process #导入Process模块
import os
def test(name):
'''
函数输出当前进程ID,以及其父进程ID。
此代码应在Linux下运行,因为windows下os模块不支持getppid()
'''
print("Process ID: %s" % os.getpid())
print("Parent Process ID: %s" % os.getppid())
if __name__ == "__main__":
'''
windows下,创建进程的代码一下要放在main函数里面
'''
proc = Process(target=test, args=('nmask',))
proc.start()
proc.join()
(2)继承Process类,修run函数代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24from multiprocessing import Process
import time
class MyProcess(Process):
'''
继承Process类,类似threading.Thread
'''
def __init__(self, arg):
super(MyProcess, self).__init__()
#multiprocessing.Process.__init__(self)
self.arg = arg
def run(self):
'''
重构run函数
'''
print('nMask', self.arg)
time.sleep(1)
if __name__ == '__main__':
for i in range(10):
p = MyProcess(i)
p.start()
for i in range(10):
p.join()
Process 的属性:
- authkey
- daemon:和线程的setDeamon功能一样(将父进程设置为守护进程,当父进程结束时,子进程也结束)。
- exitcode(进程在运行时为None、如果为–N,表示被信号N结束)。
- name:进程名字。
- pid:进程号。
例如使用daemon属性:输出结果为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self, loop):
Process.__init__(self)
self.loop = loop
def run(self):
for count in range(self.loop):
time.sleep(1)
print('Pid: ' + str(self.pid) + ' LoopCount: ' + str(count))
if __name__ == '__main__':
for i in range(2, 5):
p = MyProcess(i)
p.daemon = True
p.start()
#p.join()
print('Main process Ended!')Main process Ended!
因为主进程只输出一句话就结束了,并且我们设置了p.daemon=True,所以此时并不会等待子进程结束,类似多线程里说介绍的,我们同样可以使用join()方法,就可等待子进程完成再结束主进程了(将上面代码中p.join() 取消注释即可)。
Pool模块
Pool模块是用来创建管理进程池的,当子进程非常多且需要控制子进程数量时可以使用此模块。 Multiprocessing.Pool可以提供指定数量的进程供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行它。在共享资源时,只能使用Multiprocessing.Manager类,而不能使用Queue或者Array。
我们看看它的API:1
Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
- processes :使用的工作进程的数量,如果processes是None那么使用 os.cpu_count()返回的数量。
- initializer: 如果initializer是None,那么每一个工作进程在开始的时候会调用initializer(*initargs)。
- maxtasksperchild:工作进程退出之前可以完成的任务数,完成后用一个新的工作进程来替代原进程,来让闲置的资源被释放。maxtasksperchild默认是None,意味着只要Pool存在工作进程就会一直存活。
- context: 用在制定工作进程启动时的上下文,一般使用 multiprocessing.Pool() 或者一个context对象的Pool()方法来创建一个池,两种方法都适当的设置了context。
其包含如下实例方法:
| 方法 | 说明 |
|---|---|
| apply_async(func[, args[, kwds[, callback]]]) | 非阻塞 |
| apply(func[, args[, kwds]]) | 阻塞 |
| close() | 关闭pool,使其不在接受新的任务。 |
| terminate() | 关闭pool,结束工作进程,不在处理未完成的任务。 |
| join() | 主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用。 |
Pool使用方法:
(1)Pool+map函数1
2
3
4
5
6
7
8
9
10from multiprocessing import Pool
def test(i):
print(i)
if __name__=="__main__":
lists=[1,2,3,4,5]
pool=Pool(processes=2) #定义最大的进程数
pool.map(test,lists)#map的第二个参数必须是一个可迭代变量--如list。
pool.close()
pool.join()此写法缺点在于只能通过map向函数传递一个参数。
(2)异步进程池(非阻塞)1
2
3
4
5
6
7
8
9
10
11
12from multiprocessing import Pool
def test(i):
print(i)
if __name__=="__main__":
pool = Pool(processes=10)
for i in range(500):
pool.apply_async(test, args=(i,)) #维持执行的进程总数为10,当一个进程执行完后启动一个新进程.
print("test")
pool.close()
pool.join()
输出:
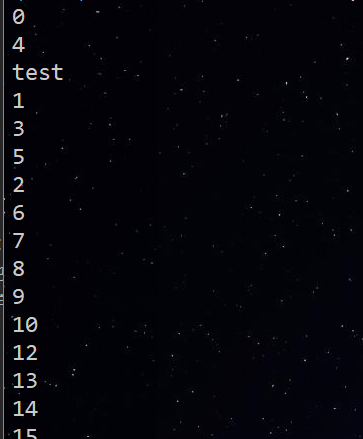
For循环中执行步骤:
- 循环遍历,将500个子进程添加到进程池(相对父进程会阻塞)
- 每次执行10个子进程,等一个子进程执行完后,立马启动新的子进程。(相对父进程不阻塞)
apply_async为异步进程池写法。
异步指的是启动子进程的过程,与父进程本身的执行(print)是异步的,而For循环中往进程池添加子进程的过程,与父进程本身的执行却是同步的。
注意:调用join之前,先调用close或者terminate方法,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束。
(3)同步进程池(阻塞)1
2
3
4
5
6
7
8
9
10
11
12
13from multiprocessing import Pool
import time
def test(i):
print(i)
if __name__=="__main__":
pool = Pool(processes=10)
for i in range(500):
pool.apply(test, args=(i,)) #维持执行的进程总数为10,当一个进程执行完后启动一个新进程.
print("test")
pool.close()
pool.join()
输出:
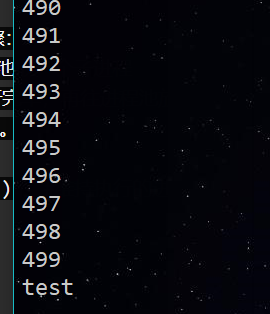
实际测试发现,for循环内部执行步骤:
- 遍历500个可迭代对象,往进程池放一个子进程
- 执行这个子进程,等子进程执行完毕,再往进程池放一个子进程,再执行。(同时只执行一个子进程)
- for循环执行完毕,再执行print函数。
(并未实现多进程并行)
queue线程安全队列
该用法和线程中的用法一样。
Lock模块
当多进程需要访问共享资源的时候,类似多线程,它同样有一个Lock类,可以避免访问的冲突。1
2
3
4
5
6
7
8
9
10
11
12
13from multiprocessing import Process, Lock
def l(lock, num):
with lock:
# lock.acquire()
print("Hello Num: %s" % (num))
# lock.release()
if __name__ == '__main__':
lock = Lock() #这个一定要定义为全局
for num in range(20):
Process(target=l, args=(lock, num)).start()
#这个类似多线程中的threading,但是进程太多了,控制不了。
父进程的全局变量能不能被子进程共享呢?答案是否定的,如果想要共享资源,可以使用manage类,或者queue模块。但这里我就有个疑问了,不是说多线程之中的内存资源是不共享的吗,那么它的Lock有什么用呢?
其使用场景可以参考这篇文章:Python的多进程锁的使用
多进程中一般是不推荐使用资源共享,如果要使用,可以参考:多进程共享资源
Pipe 管道
顾名思义,一端发一端收。Pipe可以是单向(half-duplex),也可以是双向(duplex)。我们通过mutiprocessing.Pipe(duplex=False)创建单向管道 (默认为双向)。一个进程从PIPE一端输入对象,然后被PIPE另一端的进程接收,单向管道只允许管道一端的进程输入,而双向管道则允许从两端输入。
Semaphore,信号量
其是在进程同步过程中一个比较重要的角色。可以控制临界资源的数量,保证各个进程之间的互斥和同步。
对于上述内容的详细解释,可以参考:https://cuiqingcai.com/3335.html